| Article in PDF |
"Peremennye Zvezdy", Prilozhenie, vol. 20, N 4 (2020) |
| #1. Sternberg Astronomical Institute, Lomonosov Moscow State University, Moscow,
Russia;
#2. Institute of Astronomy, Russian Academy of Sciences, Moscow, Russia; #3. Fesenkov Astrophysical Institute, Almaty, Kazakhstan. |
| ISSN 2221–0474 | DOI: 10.24411/2221-0474-2020-10017 |
Received: 19.03.2020; accepted: 22.12.2020
(E-mail for contact: khruslov@bk.ru, un7gbd@gmail.com)
|
Comments:
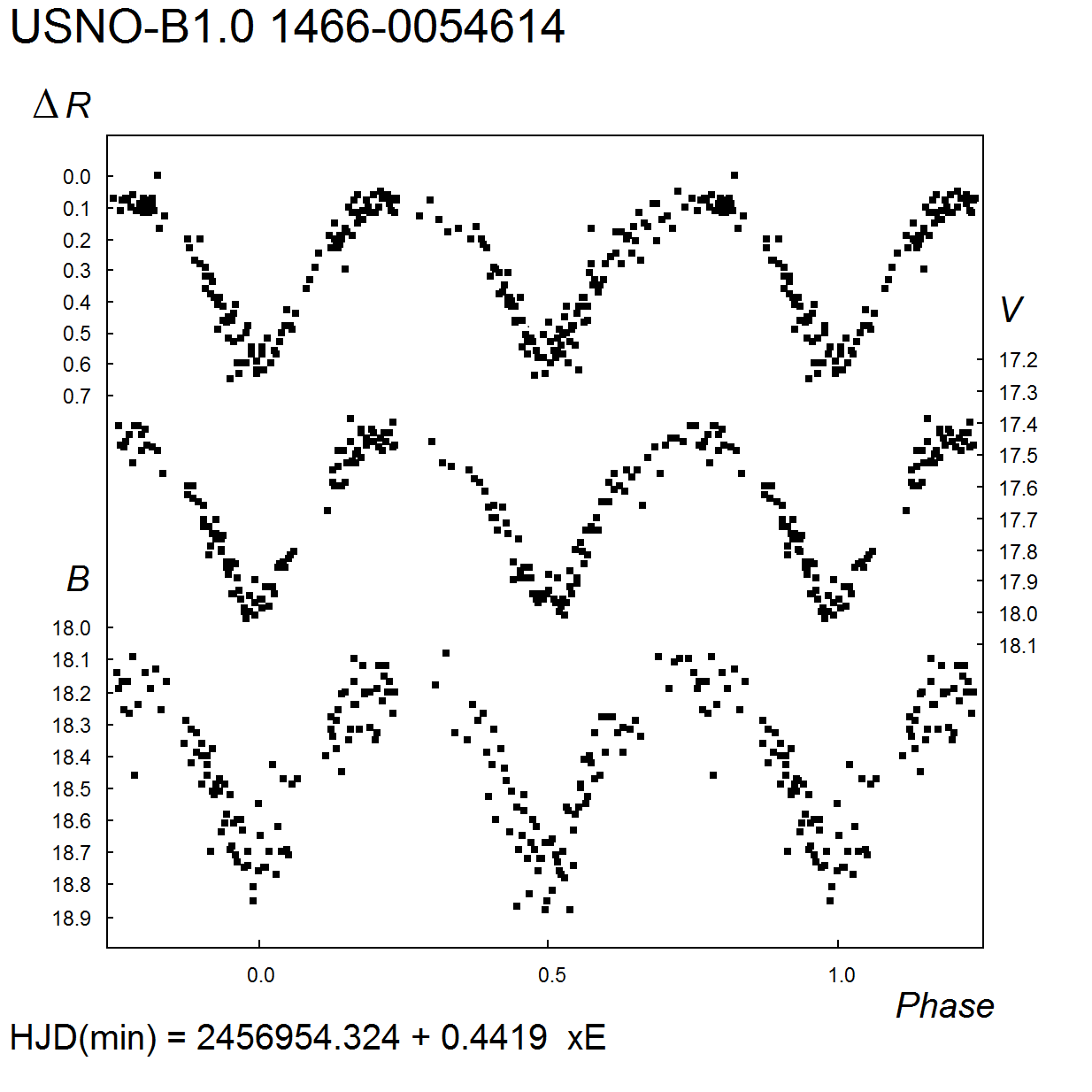
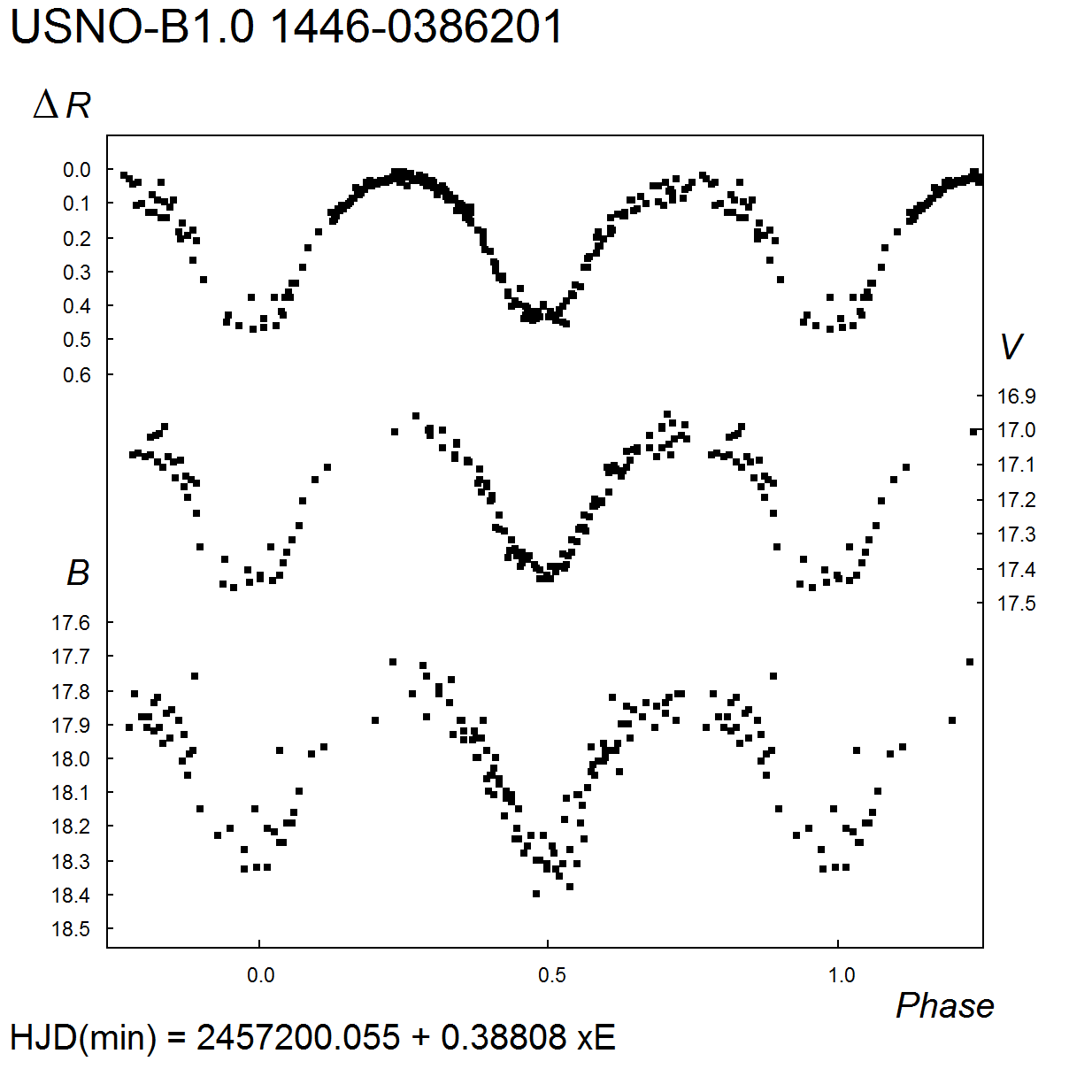
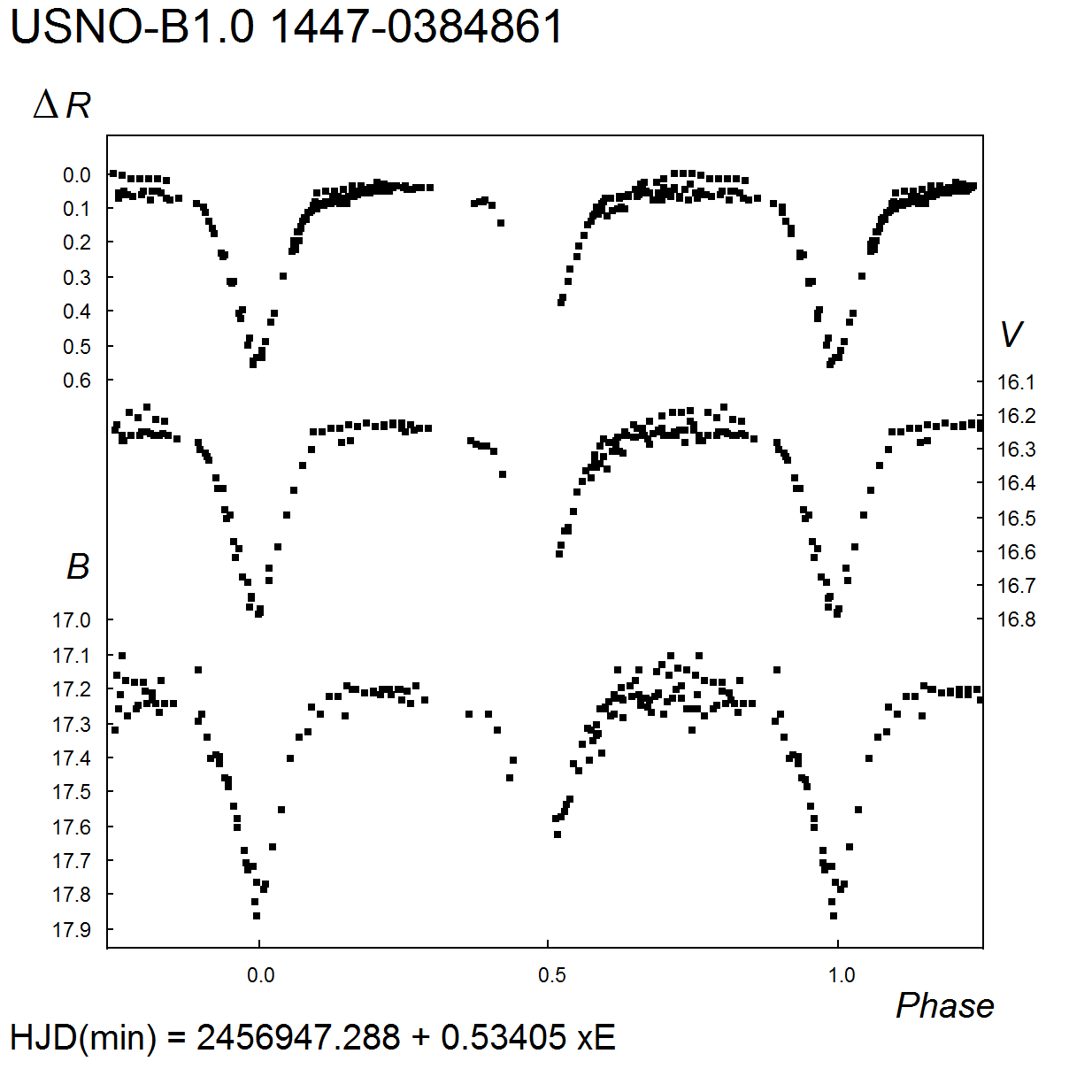
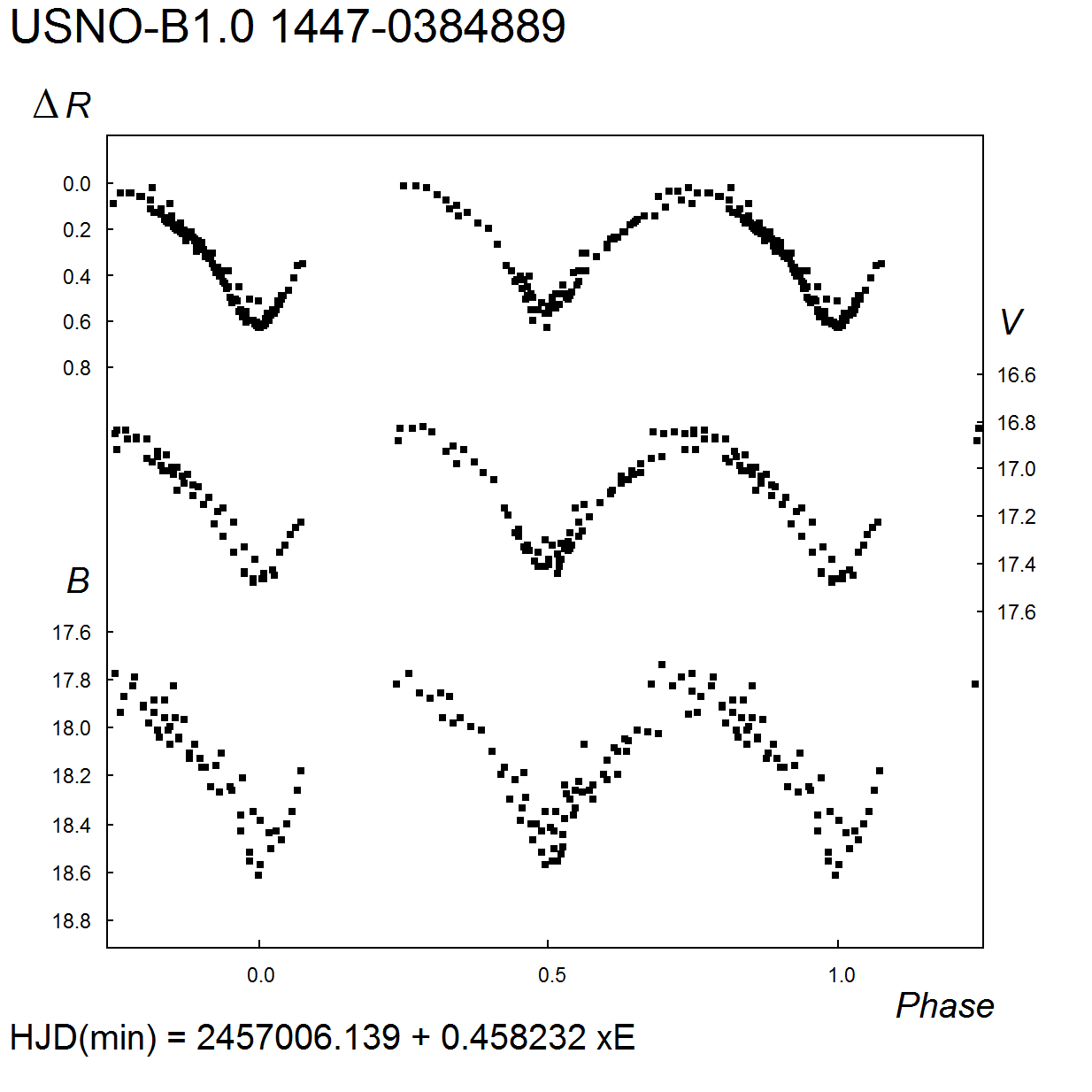
1. MinII = 17m.95 (V). For the B band, 18m.15 – 18m.7, MinII = 18m.7. for the R band, amplitude 0m.50; MinII = 0m.48 (delta R).
2. MinII = 18m.40 (V). For the B band, 19m.35 – 20m.1, MinII = 19m.9; for the R band, amplitude 0m.63.
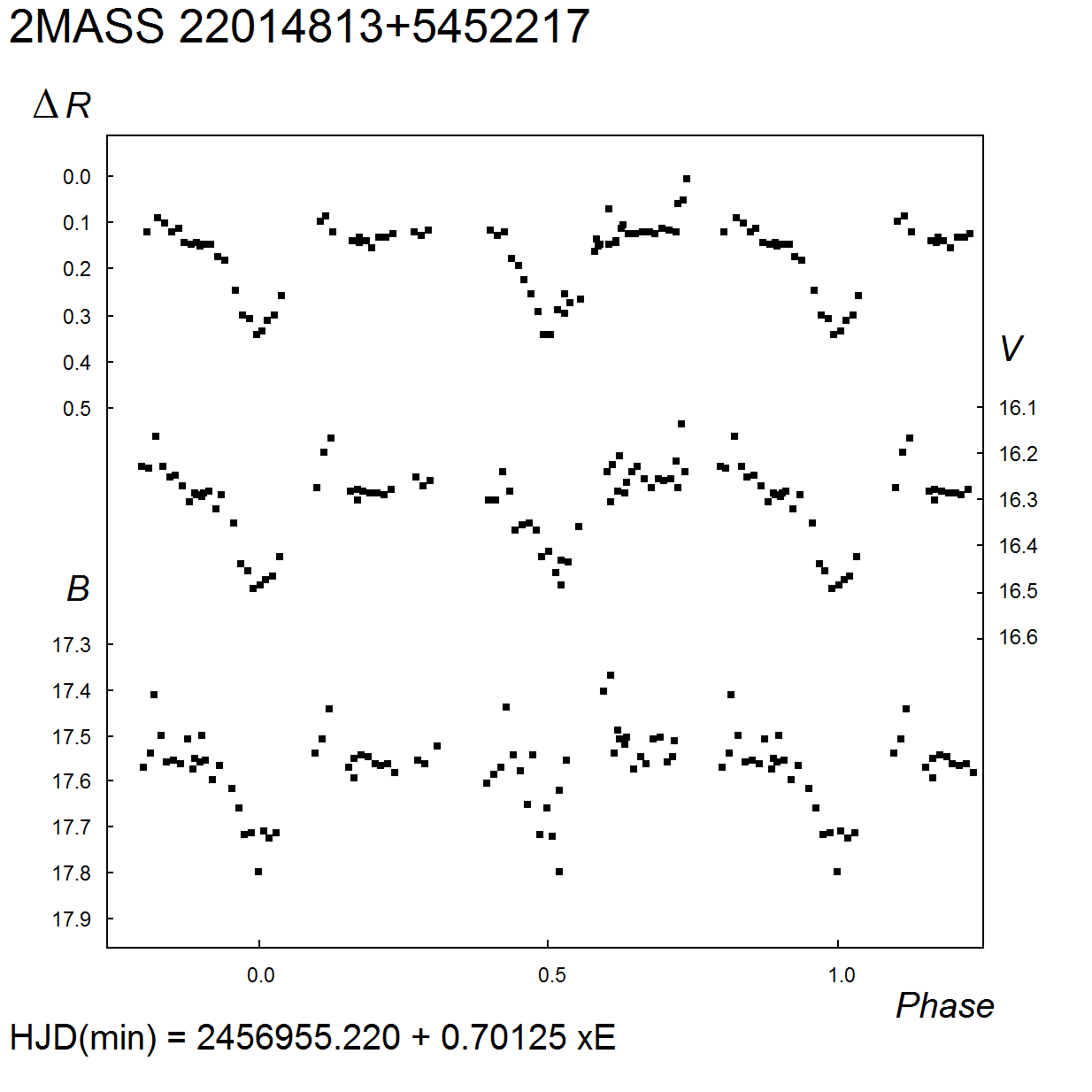
3. D = 0.16 P. MinII = 16m.46 (V). For the B band, 17m.52 – 17m.76: ; for the R band, amplitude 0m.24, MinII = 0m.24 (delta R). Close companion (distance 6″) 2MASS 22014778+5452166, in USNO-B1.0 catalog pair is not resolved.
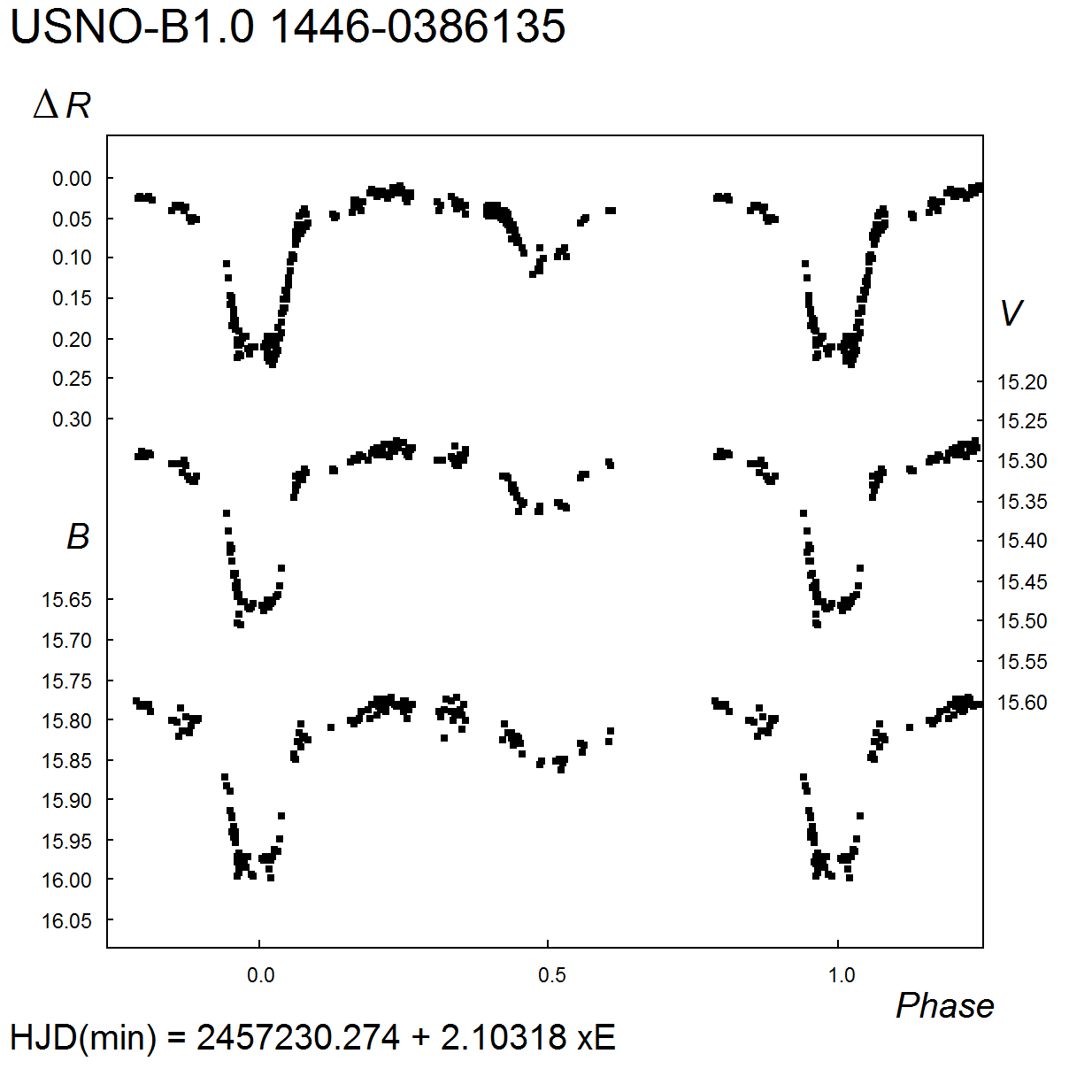
4. D = 0.14 P. MinI exhibits s total eclipse, d = 0.06 P. MinII = 15m.36 (V). For the B band, 15m.78 – 15m.99, MinII = 15m.86; for the R band, amplitude 0m.20, MinII = 0m.09 (delta R).
5. MinII = 17m.42 (V). For the B band, 17m.81 – 18m.32, MinII = 18m.32; for the R band, amplitude 0m.45, MinII = 0m.42 (delta R);
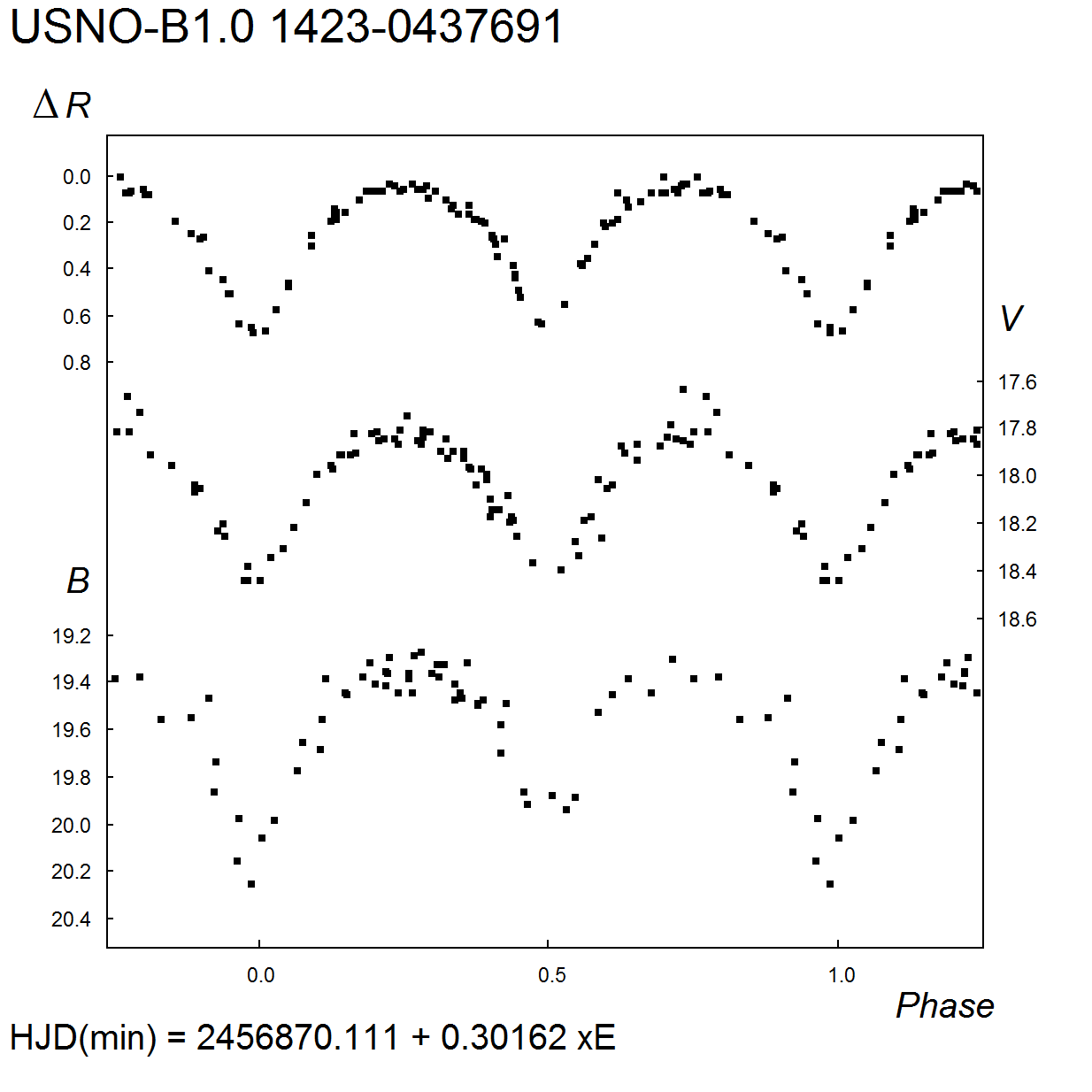
6. D = 0.19 P. For the B band, 17m.15 – 17m.80; for the R band, amplitude 0m.54.
7. MinII = 17.41 (V). For the B band, 17m.85 – 18m.5, MinII = 18m.45; for the R band, amplitude 0m.63, MinII = 0m.57 (delta R)Remarks:
We present our discovery of seven new eclipsing binaries. Our CCD observations in the Johnson B, V and R bands were performed at the Tien Shan Astronomical Observatory of the V.G. Fesenkov Astrophysical Institute, at the altitude of 2750 m above the sea level. Our observations were performed with the eastern Zeiss 1000-mm reflector (the focal length of the system was 6650 mm; the detector was an Apogee U9000 D9 CCD camera; the chip was cooled to –40°C).
Reductions were performed using the MaxIm DL aperture photometry package. Magnitudes of the comparison stars (in Johnson's B and V bands) were taken from the AAVSO Photometric All-Sky Survey (APASS) catalog. The R-band observations could be presented only as magnitude differences with respect to the comparison star. In the Comments for the R band, the total variability amplitude is given.
These observations were analyzed using the period-search software developed by Dr. V.P. Goranskij. The coordinates were drawn from the Gaia DR2 catalog (Gaia Collaboration et al. 2018). All studied stars are not detected as a variables in Gaia DR2 project. The variables were classified according to the GCVS classifications (Samus et al. 2017).
The light elements for one star (No. 4) were calculated using ASAS-SN data (Shappee et al. 2014 and Kochanek et al. 2017)
Acknowledgments: The authors are grateful to Dr. V. P. Goranskij for providing light-curve analysis software. We wish to thank M.A. Krugov, N.V. Lichkanovsky, I.V. Rudakov, and R.I. Kokumbaeva for their assistance during the observations. This study was carried out within the framework of Project No. BR05236322 "Studies of physical processes in extragalactic and galactic objects and their subsystems", financed by the Ministry of Education and Science of the Republic of Kazakhstan.References:
Gaia Collaboration, Brown, A.G.A., Vallenari, A., et al., 2018, Astron. and Astrophys., 616, A1
Kochanek, C. S., Shappee, B. J., Stanek, K. Z., et al., 2017, Publ. Astron. Soc. Pacific, 129, 104502
Samus, N.N., Kazarovets, E.V., Durlevich, O.V., Kireeva, N.N., Pastukhova, E.N., 2017, General Catalogue of Variable Stars: Version GCVS 5.1, Astron. Rep., 61, No. 1, 80
Shappee, B. J., Prieto, J. L., Grupe, D., et al., 2014, Astrophys. J., 788, 48
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}