В.П.Ильин, доктор физико-математических наук, профессор,
главный научный сотрудник
Института вычислительной математики и математической геофизки СО РАН.
Опубликовано в журнале "Природа", N 6, 1999 г.
| Содержание
|
Основная методология реализации вычислительных процессов на многопроцессорных
компьютерных системах - это выявление таких счетных фрагментов алгоритма, которые
можно выполнить одновременно на различных арифметических устройствах при минимальных
информационных обменах между ними. Это объясняется чисто техническими деталями: время
обмена массивов из m чисел между двумя соседними процессорами, которые имеют
непосредственную физическую связь, можно выразить как
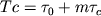 , ,
где 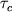 есть
длительность передачи одного числа, а есть
длительность передачи одного числа, а 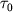 - время стартовой коммуникационной задержки.
Если через - время стартовой коммуникационной задержки.
Если через 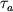 обозначить усредненное время выполнения одной арифметической операции, то
обычно имеем обозначить усредненное время выполнения одной арифметической операции, то
обычно имеем 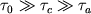 , где конкретные соотношения времен могут меняться, но в главном
эти неравенства сохраняются. , где конкретные соотношения времен могут меняться, но в главном
эти неравенства сохраняются.
Если не вдаваться в глубокие тонкости отображения алгоритмов на архитектуру
вычислительной системы, эффективность распараллеливания можно выразить количественно
двумя основными характеристиками - коэффициентами ускорения и загрузки процессоров:
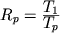 , , 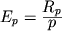
где T1, Tp - интервалы времени выполнения алгоритма (или задачи) на одном и p процессорах,
причем Tp оценивается с учетом коммуникационных потерь.
Надо подчеркнуть, что ускорение алгоритма и задачи могут быть разными, поскольку для
решения последней может оказаться целесообразным выбрать метод, который требует
большего объема вычислений, но лучше распараллеливается.
Если рассматривать проблему распараллеливания решений многомерных краевых задач в
целом, то решение СЛАУ также один из главных этапов, так как другие расчетные стадии -
дискретизация области, аппроксимация дифференциальных уравнений и обработка результатов
- распараллеливаются гораздо легче. Тривиально распараллеливаются и простейшие
итерационные алгоритмы, но они имеют слишком плохую скорость сходимости. Трудности в
реализации наиболее быстрых методов заключаются в том, что они основаны на выполнении
различных рекуррентных соотношений, являющихся сугубо последовательными операциями.
Наиболее перспективный подход к распараллеливанию краевых задач заключается в
декомпозиции расчетных областей на подобласти с возможно одинаковым количеством узлов в
каждой. При этом общая задача разбивается на подзадачи, каждая из которых решается на
своем процессоре, с организацией периодических информационных интерфейсов между ними.
Если решается СЛАУ, то в каждой подобласти итерируется соответствующая подсистема, что
приводит в итоге к двойному итерационному процессу.
На примере декомпозиции трехмерных задач можно проследить ряд важных
методологических вопросов, тесно связанных с чисто архитектурными компьютерными
аспектами. Вычислительная сеть может представлять собой одномерную сетку, двумерную
прямоугольную или трехмерную параллелепипедоидальную, когда каждый процессор
физически связан соответственно с двумя, четырьмя или шестью топологически соседними
процессорами (мы не будем рассматривать другие экзотические и более дорогие сети типа
гиперкуб и "каждый с каждым").
Теперь, если у нас есть трехмерная расчетная сеточная
область с числом узлов N=K3, много большим количества процессоров p, то как лучше ее
разбить на подобласти с точки зрения оптимальности распараллеливания?
Ответ зависит от соотношения времен Ta и Tc, затрачиваемых такими вычислительными
системами соответственно на выполнение арифметических операций и обмен данными между
процессорами. А это связано с чисто геометрическими факторами. Величина Ta при
вычислении одной итерации пропорциональна общему числу узлов подобласти K3/ p, т.е. ее
объему, а значение Tc пропорционально количеству граничных узлов, смежных с соседними
подобластями. При использовании одномерной вычислительной сети область разбивается на
"пластины" с площадью двух смежных граней (числом граничных узлов), равной 2K2. В случае
"двумерной" декомпозиции - на "столбики", площадь смежных граней которых
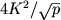 (здесь предполагается компьютерная сеть с числом процессоров (здесь предполагается компьютерная сеть с числом процессоров 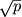 в каждом из двух
измерений). Наконец, при определении подобластей в виде "кубиков с длиной ребра Kp-1/3"
величина Tc пропорциональна 6K2p-2/3. Таким образом, при в каждом из двух
измерений). Наконец, при определении подобластей в виде "кубиков с длиной ребра Kp-1/3"
величина Tc пропорциональна 6K2p-2/3. Таким образом, при 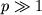 с точки зрения
коммуникационных потерь "одномерная" декомпозиция оказывается наихудшей, а трехмерная
- наилучшей. с точки зрения
коммуникационных потерь "одномерная" декомпозиция оказывается наихудшей, а трехмерная
- наилучшей.
Разумеется, здесь "за кадром" остается много других вопросов и возможностей:
совмещение во времени обменов процессора с несколькими соседними, одновременное
выполнение обменов и вычислений, использование сверхбыстрой кэш-памяти, конвейеризация
арифметических операций в отдельном процессоре, если он содержит, например, несколько
сумматоров и множительных устройств.
Эффективная реализация параллельных алгоритмов предполагает грамотное
использование архитектуры компьютера и систем программирования, что значительно
повышает планку требований к квалификации прикладного математика-программиста. С
прагматической точки зрения это, конечно, крупный недостаток, и на преодоление таких
накладных расходов ориентированы существующие и развиваемые средства автоматизации
распараллеливания, которые в идеале должны полностью скрыть от пользователя внутреннюю
технологическую "кухню", при сохранении высоких коэффициентов Rp и Ep.
Разумеется, мы не могли исчерпать обилия интереснейших вопросов даже в рамках
методов неполной факторизации. В первую очередь - проблемы распространения полученных
результатов на более общие задачи: нерегулярные сетки, матрицы с менее сильными
свойствами и усложненными структурами, краевые задачи для систем дифференциальных
уравнений и т.д.
Кроме того, обсуждавшиеся алгоритмы развиваются одновременно с другими
перспективными направлениями, среди которых - многосеточные методы, альтернирующие
операторные принципы, многоуровневые иерархические итерации. И здесь, кроме здоровой
конкуренции, - неизбежно взаимное обогащение с проникновением идей и конструктивных
подходов. При существующем росте научных школ и бурном потоке исследований трудно
загадывать их тенденции даже на не очень далекое будущее, но текущий период можно без
преувеличения назвать золотым веком вычислительной алгебры.
Статья написана по результатам исследований, поддержанных грантом РФФИ 95-01-01770 "Методы
решения систем линейных алгебраических уравнений высокого порядка с разреженными
матрицами".
Назад
Написать комментарий
|
